Had a third party (that did not have any experience with product failure rates / history) conduct a DFMEA on a protection relay. The team identified 4 failure modes with RPN above acceptable levels. Turns out those 4 failure modes are on the units top 10 for service calls and repairs.
Even if not used as part of a Reliability Centred Enterprise Management Strategy DFMEAs provide great value.
Friday, 22 July 2011
Friday, 15 July 2011
Design Failure Modes Effects Analysis - Issues Down, Margins Up
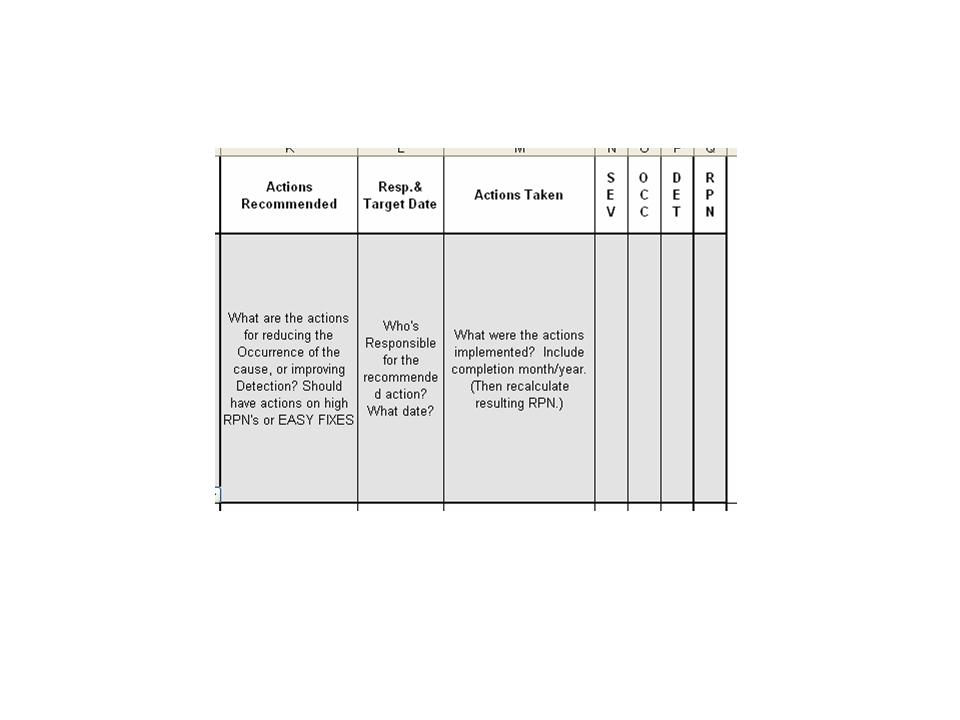
The previous blog outlined the steps in completing a DFMEA; today we will review how to complete a DFMEA template.
Hopefully you'll see how easy it is to consolidate issues, assign rankings and control / mitigate your risks.
The first portion of the template outlines the component name, function, potential failure modes and the potential effects of the failure.

Once each step, failure mode and failure mode effect is listed for each component it is time to assign a severity number (on a relative scale of 1 to 10 - see previous blog for ranking definition).

With the Severity ranking complete the next step is to add the potential causes of each failure and the likelihood of their occurrence (on a relative scale of 1 to 10 - see previous blog for ranking definition).


The next step is calculating the RPN - Risk Priority Number by multiplying the Severity X Occurrence X Detection.

Wednesday, 13 July 2011
Design Failure Modes Effects Analysis - THE TOOL TO USE
One of the RCEM tools described in the last blog was the Design Failure Mode Effects Analysis (DFMEA) methodology.
DFMEA is an analysis tool utilized to explore and document ways that a product might fail in real-world applications / use.
The development of a DFMEA is predominantly a team effort and, contrary to popular belief, it’s not simply an engineering responsibility.
DFMEAs document:
- the key functions of a product,
- the potential failure modes relative to each function
- and the causes of each failure mode.
The DFMEA methodology allows one to document what is known and contemplate a product's potential failure modes prior to completing any design work. The information is then utilized to mitigate risks, design out failure modes and increase product reliability.
DFMEAs are (ideally) conducted at the earliest stages of concept development and are used as an iterative tool to select between competing designs or concepts.
Though DFMEAs are specific to design, PFMEAs (process) and MFMEA (manufacturing) help identify/mitigate processing and assembly risks. Having operations and supplier management staff join in on the DFMEA development is often well received and adds significant value.
Conducting a DFMEA
Review the design
- Drawings / schematics of the design/product or prototype/mock up
- Identify each component
- Identify each interface
Brainstorm potential failure modes
- Review existing documentation
- Pull failure data from previous generation products
- Compare failure modes from similar products
- Use customer complaints, warranty reports, and reports that identify things that have gone wrong, such as hold tag reports, scrap, damage, and rework, as inputs for the brainstorming activity
List the potential effects of failure
- What happens is the component / interface results in a failure
- There may be more than one for each failure; product can not function, limited functionality, appearance issue (works fine), etc
Assign a Severity rankings
- The severity ranking is based on a relative scale ranging from 1 to 10.
- A “10” means the effect has a dangerously high severity leading to a hazard without warning.
- A severity ranking of “1” means the severity is extremely low.
- This is a relative scale, not an absolute.
- Assigning severity rankings is critical. Severity rankings are the basis for determining risk of not only a potential failure mode but the interaction of different failure modes.
- Note: once you have established the Severity Ranking System it should be used for every product throughout the organization – it should be done once; as a company wide exercise so that all departments and projects are ranked consistently (and can be compared).
Assign an Occurrence rankings
- Like the Severity Ranking the Occurrence Ranking is a relative 1 to 10 scale, based on how frequently the cause of the failure is likely to occur.
- An occurrence ranking of “10” means the failure mode occurrence is very high; it happens all of the time. Conversely, a “1” means the probability of occurrence is remote.
- Occurrence Rankings can also be developed with three different ranking options (time-based, event-based, and piece-based) and select the option that applies to the design or product.
Assign Detection rankings
- Based on the chances the failure will be detected prior to the customer finding it
- Think of the detection ranking as an evaluation of the ability of the design controls to prevent or detect the mechanism of failure.
- To assign detection rankings, consider the design or product-related controls already in place for each failure mode and then assign a detection ranking to each control.
- A detection ranking of “1” means the chance of detecting a failure is almost certain.
- “10” means the detection of a failure or mechanism of failure is absolutely uncertain.
Calculate the RPN for each issue
- Severity x Occurrence x Detection.
- The RPN gives us a relative risk ranking. The higher the RPN, the higher the potential risk.
Develop an action plan
- Define who will do what by when.
Take action
- Implement the improvements identified by your DFMEA team.
Calculate the resulting RPN
- Once improvements are made re-evaluate each of the potential failures
- Calculate the new RPNs
Repeat until the product is optimized
Monday, 11 July 2011
RCEM - questions to ask at the design phase
RCEM is very much a systems approach and like with every other system it’s easier to start at the beginning during the design phase than going back to make adjustments once the system has been developed.
Some topics that apply to RCEM at the design phase (to be reviewed in greater detail in future blogs) include:
• Design / Performance
• Where to look:
• Performance data will be disbursed throughout the organization, no one department will have the information required, you’ll more than likely have to dig into various databases, binders, work sheets
• Even with company wide commercial software in place individuals still run on excel, word and email to track issues; finding this information is like finding the ‘unmarked trail’ on a hiking map – they’re tough to find, people don’t want to share them but they’re the holy grail
• Unfortunately even with company wide systems the concept of making data a corporate asset has not been fully adopted in many (many) organizations
• Tools to use:
• If you’re looking for design / performance tools google the following:
• DFMEA – Design Failure Mode Effects Analysis
• PFMEA – Process Failure Mode Effects Analysis
• DFSS – Design for Six Sigma
• Odds are these tools haven’t been utilized in the design process subsequently you won’t find any documentation – the key here is to learn the tools, at least the theory and start asking questions that relate to Failure Modes – probability of occurrence, severity of a failure, likelihood of detection
• More on these tools in future blogs
• Capability / Capacity
• Segregate Marketing Materials from Engineering Data Sheets
• Many times marketing materials will disguise themselves as technical, they’ll say all the right things but they are marketing materials – get to the specifications, pull up Service / Technical Bulletins
• Flexibility
• Flexibility always sounds great but beware, many products really require a specific focus
• Buying OEM products – many are repackaged versions of other ‘family products’ they’ll have the same issues and failure modes
• Availability / Dependability – R & M
• Data, Data, Data – you have to look at the organization’s data collection techniques to make these calculations and validate the results
• Supportability
• What does it take to support the product (it’s not an easy question); there are a number of departments, people, processes behind the scenes that support the product and need to be taken into accoun
• Standardization
• This is a topic for an entirely new blog entry – standardization is key, it is fundamental, it’s a focus that is imperative
• Producibility
• Can it be made and made efficiently
• Servicability
• What does it take to service the product; does it have to be entire dismantle for service, can it be serviced remotely, is there special tools / training
There are many questions that need to be asked during the design phase – during the coming weeks we’ll review the tools that can be used to ask those questions and collect the required information.
Monday, 4 July 2011
RCEM in Formula 1
Had an interesting conversation with an engineer wrt reliability in Formula 1. He supported the comment that reliability in Formula 1 increased greatly over the past few years and that that could be attributed to the engineering design work and testing (he's a mechanical designer). Since I subscribe to the RCEM philosophy I took a little broader look and though there is no doubt that design and innovation are big contributors to reliability I mentioned that he overlooked the specification; whereas in previous years Formula 1 teams were permitted to run their engines to over 22,000 rpm they are currently limited to 18,000 rpm. That reduction of 4000 rpm (probably more than what your average car peaks at during a normal drive) results in less stress on the engines. Not being pushed to the 22,000 rpm limit for a 300 kilometer race adds considerably to the reliability and durability of an engine.
Considering that a Formula 1 engine produces roughly 1000 horsepower and 100,000 BTU per minute, more than 650 liters of air per second are inhaled in to the engine and they travel just over 1 kilometer on 1 liter of fuel any change to demands on performance will impact reliability and costs.
Taking a holistic view of system performance helps identify causes and contributors to increased reliability and availability and reduction in costs.
Considering that a Formula 1 engine produces roughly 1000 horsepower and 100,000 BTU per minute, more than 650 liters of air per second are inhaled in to the engine and they travel just over 1 kilometer on 1 liter of fuel any change to demands on performance will impact reliability and costs.
Taking a holistic view of system performance helps identify causes and contributors to increased reliability and availability and reduction in costs.
Friday, 24 June 2011
Release Notes
Not everyone reads the Release Notes that are issue with OEM Firmware Upgrade Announcements; after this we hope you will, and if you already do, will look at them in a different light.
We took 18 months of Release Notes from an OEM supplying products (in this case relays) to the Utility Market and found some very interesting trends.
- 27% of the release notes indicated issues with metering, records and communications
- 16% of the release notes clearly stated that protection would be / was compromised - "protection may operate when it should not", "protection may not operate when it should", "protection is not available".
- 3% related to equipment rebooting unexpectedly
The impact of these issues on an organization are easily characterized by the 'iceberg' diagram, there's a whole bunch under the water line that you can't see.
The issues impact everyone from engineering to maintenance, operations to finance. When products do not perform to specification and upgrades are required the actual upgrade costs are the smallest contributor in the cost equation. Lost time in trouble-shooting, asset tracking, scheduling downtime, carrying more risk than necessary (until the fix can be applied), managing suppliers, inventory and implementation schedules, purging inventory, reviewing and updating data records to remove any contaminated data points (to ensure proper trending and forecasting in the future), all dwarfed by the cost (inability to deliver, income, safety, clean up, reputation, fines, etc) of downtime should a failure occur.
Release Notes are a great source of information. Individually they have value, collectively they are invaluable.
As with Service Bulletins, applying RCEM philosophies and ensuring all organizational functions interact for the overall effectiveness of the system is paramount.
This study was specific to the Utility Market however SKUs from the the same family of products are used in Oil & Gas, Mining and Heavy Industrial Applications.
www.RCEM.ca
We took 18 months of Release Notes from an OEM supplying products (in this case relays) to the Utility Market and found some very interesting trends.
- 27% of the release notes indicated issues with metering, records and communications
- 16% of the release notes clearly stated that protection would be / was compromised - "protection may operate when it should not", "protection may not operate when it should", "protection is not available".
- 3% related to equipment rebooting unexpectedly
The impact of these issues on an organization are easily characterized by the 'iceberg' diagram, there's a whole bunch under the water line that you can't see.
The issues impact everyone from engineering to maintenance, operations to finance. When products do not perform to specification and upgrades are required the actual upgrade costs are the smallest contributor in the cost equation. Lost time in trouble-shooting, asset tracking, scheduling downtime, carrying more risk than necessary (until the fix can be applied), managing suppliers, inventory and implementation schedules, purging inventory, reviewing and updating data records to remove any contaminated data points (to ensure proper trending and forecasting in the future), all dwarfed by the cost (inability to deliver, income, safety, clean up, reputation, fines, etc) of downtime should a failure occur.
Release Notes are a great source of information. Individually they have value, collectively they are invaluable.
As with Service Bulletins, applying RCEM philosophies and ensuring all organizational functions interact for the overall effectiveness of the system is paramount.
This study was specific to the Utility Market however SKUs from the the same family of products are used in Oil & Gas, Mining and Heavy Industrial Applications.
www.RCEM.ca
Thursday, 23 June 2011
value in categorizing Service Bulletins

We reviewed 10 (random) OEM Service Bulletins for products deployed in the Utility Market and applied the RCEM philosophy to categorize the Bulletins wrt what departments needed to either 'be aware' of the information contained, or 'take action' based on the details of the bulletins.
It was interesting to note the 'distribution list' of functions / departments that would not only benefit from the information but really required the data in order to perform their duties effectively.
In reality the distribution list for many organizations does not look similar. For many companies Service Bulletins enter the organization via Engineering or Asset Management, are filed or added to a data repository (in many cases with restricted access) and are only actively shared when categorized as a 'high' risk; with the definition of 'high' varying.
This study was specific to the Utility Market however SKUs from the the same family of products are used in Oil & Gas, Mining and Heavy Industrial Applications.
www.rcem.ca
Wednesday, 22 June 2011
Service Bulletins and RCEM
Taking a look at a series of Service Bulletins from a Utility Product OEM (relays) we found that the bulletins referenced:
This study was specific to the Utility Market however SKUs from the the same family of products are used in Oil & Gas, Mining and Heavy Industrial Applications.
- relay will reboot
- potential for misoperation
- false trip
- power supply failure
- inability to communicate
The Utility we studied had a point of contact for the Supplier and that position received all Service Bulletins. The bulletins were filled with Asset Management and were not making their way throughout the rest of the organization. Operations were replacing product with like product (had the same issue), service was trouble shooting when in fact the issue was already known (though not communicated to them), control centers were noting issues and allocating resources for issues that were again known but not communicated, risk mitigation strategies were not complete as the Risk Management Team were not in the loop on issues.
One of the main benefits of RCEM is understanding the interaction points among departments to ensure optimal system performance.
This study was specific to the Utility Market however SKUs from the the same family of products are used in Oil & Gas, Mining and Heavy Industrial Applications.
www.RCEM.ca
Tuesday, 21 June 2011
RCEM Group on linkedin
Join the RCEM Group on linked in
http://www.linkedin.com/groups?gid=3963468&trk=hb_side_g
http://www.linkedin.com/groups?gid=3963468&trk=hb_side_g
Subscribe to:
Posts (Atom)